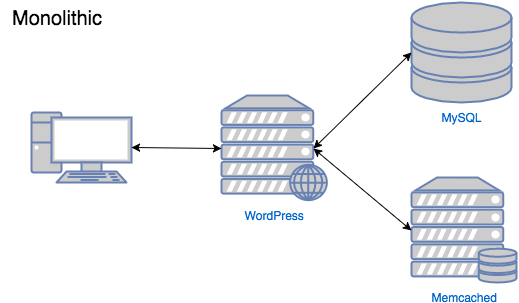
Та нэг энгийн web server болон өгөгдлийн сангаас бүтэх систем хийлээ гэж үзье. Хэрвээ тэр систем чинь ачаалал даахгүй байвал яах вэ?
Хэрвээ web server чинь ачааллаа даахгүй байгаа бол шийдэхэд амархан Яг адилхан 1 instance үүсгэхэд л хангалттай.
Харин өгөгдлийн сан чинь ачааллаа дийлэхгүй бол шийдэхэд нэлээн яривигтай. Мэдээж эхний алхам бол бүх хандалт(query)-аа optimization хийх, хэд хэдэн давхар cache давхарга нэмэх.
Ихэнх системийн хувьд өгөгдөл унших тоо нь бичих тооноосоо хэд дахин, эсвэл хэдэн арав дахин их байдаг. Жишээ нь, хүмүүс Facebook-ын profile-аа сардаа эсвэл бараг жилдээ 1 л өөрчилдөг байх. Харин тэр хүний profile-ыг өдөрт хэдэн арваас, хэдэн зуун хүн харж байгаа. Тиймээс, таны хийж буй систем чинь, яг үүнтэй адил уншилтын тоо нь бичилтийн тооноосоо хамаагүй их бол, master-slave загвар луу шилжүүлж болох юм.
Master Толгой өгөгдлийн сан ба, бүх бичилтүүд ийшээ хийгдэнэ
Slave Дагавар өгөгдлийн сан ба, бүх уншилтууд эндээс хийгдэнэ
Ажиллах зарчим нь маш энгийн. Master луу бичилт хийх болгонд master нь slave-үүд рүүгээ давхар бичилт хийгээд шинэчлээд, бүх server дээрх мэдээлэл яг адил мэдээлэл агуулаад явах юм. Үүнийг replication гэж нэрлэдэг. Харин одоо их хэмжээний унших хүсэлт ирэхэд slave-үүд рүүгээ тэнцүү хуваагаад явуулчихна. Дараах зурганд дүрслэх гэж оролдлоо.

Ихэнх төрлийн өгөгдлийн сангууд replication хийх чадвартай бөгөөд, ихэнхдээ 2 төрөл байдаг. Sync болон async. Sync replication нь бичих хүсэлт авангуутаа slave-үүдээ шинэчлэх бөгөөд, шинэчилж дууссаны дараа, бичилт амжилттай боллоо гэсэн хариултыг буцаана. Харин async нь, master дээр бичилтээ хийсэний дараа бичилт амжилттай боллоо гэсэн хариуг буцаагаад, дараа нь slave-үүдээ шинэчилнэ.
2 арга нь 2-уулаа сайн ба муу талуудтай бөгөөд, хамгийн гол анхаарах ёстой зүйл гэвэл consistency юм. Async үед inconsistent буюу, нэг агшинд нэг өгөгдөл, 2 өөр утга агуулах боломж үүсч байгаа юм. Өөрөөр хэлбэл дөнгөж бичсэний дараа, уншилт хийвэл хуучин утга уншигдах магадлалтай гэсэн үг.
Харин одоо, бүүр их ачаалаллын талаар ярилцая. 100 сая хэрэглэгчийн мэдээлэл хадгалах ёстой гэж үзье. Урьдчилсан тооцооны дүнд 10 сая хэрэглэгчийн мэдээлэлийг 1 server-т хадгалахад ачаалал даана гэж үзье. Тэгвэл одоо бидэнд 1 биш 10 master хэрэг болно. Өөрөөр хэлбэл 1 том хүснэгтийг 10 жижиг хэсэг болгож хувааж байнаа гэсэн үг. Үүнийг sharding гэх бөгөөд, хуваагдсан хэсгүүдийг shard гэнэ. Дараах зурганд дүрслэв.

Янз бүрийн байдлаар хувааж болно. Жишээ нь 1-1000000 ID-тай хэрэглэгчийг Master 1-д, 10000001-20000000 ID-тай хэрэглэгчдийг Master 2-т гэх мэт. Эсвэл 10-т хуваагаад гарах үлдэгдлээр нь 10 master-руугаа хувааж болно. Эсвэл хэрэглэгчийн амьдарч буй улсаар нь гэх мэт, хамгийн гол нь системдээ тааруулаад, яаж хуваавал хамгийн хялбар аргаар хүссэн мэдээлллээ авч чадах вэ, мөн ачаалал болон, мэдээллийн хувьд тэнцвэртэй баланстай байж чадах уу гэдгийг бодох хэрэгтэй.
Жишээ нь Facebook дээрх post-ын comment-ыг хадгалах ёстой гэж үзье. Тэгвэл comment-ынх нь ID-аар биш, post-ынх нь ID-г ашиглан sharding хийвэл, адил post дээрх бүх comment-ууд нэг server дээр хадгалагдах тул, comment-уудыг уншихын тулд, олон server-рүү хандах шаардлагагүй болох юм.
Эцэст нь нэг юм хэлэхэд, энд нэг ч өгөгдлийн сангийн нэр(MySQL, MongoDB гэх мэт) дурдаагүй байгааг анзаарсан байх. Ямар ч өгөгдлийн сан дээр, автомат sharding байсан ч, ард нь нэг иймэрхүү л зүйл явагдаж байгаа гэдгийг ойлгуулах гэсэн юм. KVS төрлийн NoSQL-уудын хувьд, key-ийнхээ hash-аар хуваадаг ба ихэнх нь автоматаар, эсвэл хангалттай их library-ууд байдаг тул хөгжүүлэгч талаас нээх асуудал гараад байхгүй. Харин RDBMS-үүдийн хувьд, системийн шаардлага янз бүр тул, бараг өөрсдөө системдээ тохирсон sharder хөгжүүлж таарах байх.