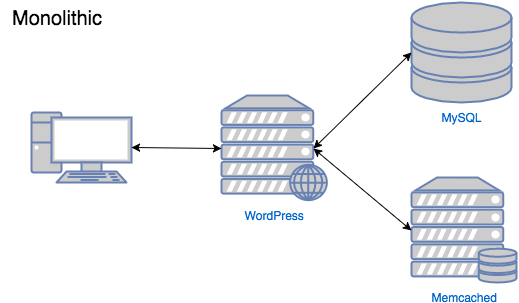
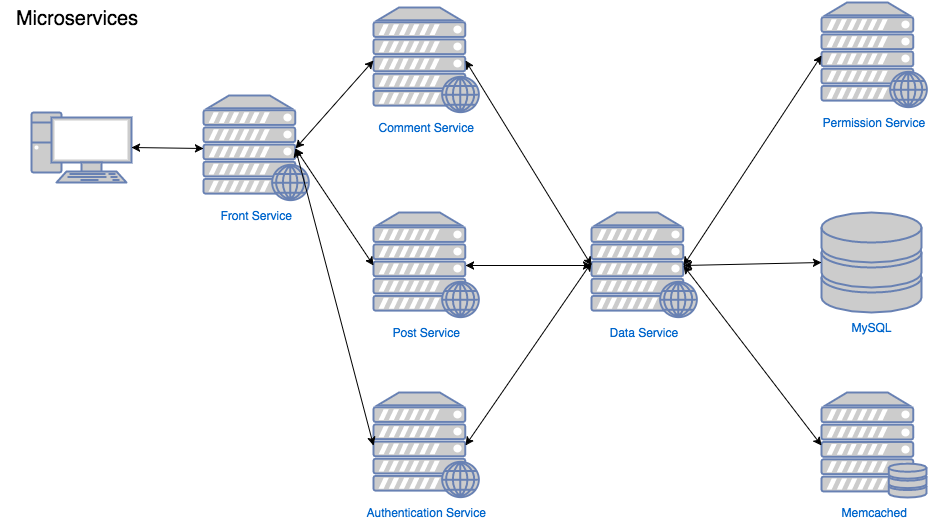
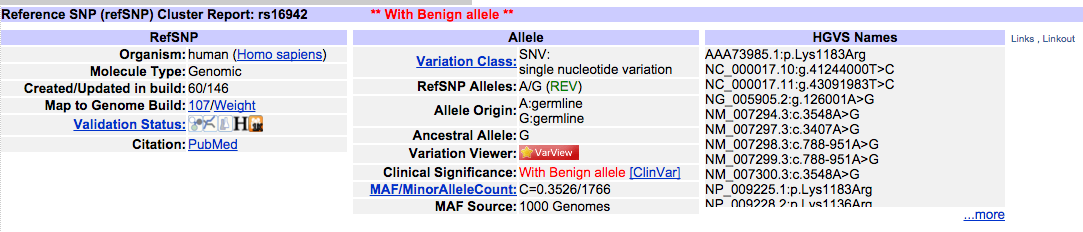
Унтах гэсэн чинь нойр хүрдэггүй.
Зүгээр сууж байхаар, яаж яваад Парист ирчихсэн талаараа бичье гэж бодлоо.
Токио ч дажгүй газар л даа. Тэгэхдээ таарах хүн, таарахгүй хүн гэж байдаг санагддаг. 10 жил Японд амьдарчихаад таараагүй гэх нь хайшаа ч юм. Тэгэхдээ удаан хугацаанд Японд амьдарч байгаад, хэсэг өөр улсад амьдраад, өөр амьдралын хэмнэлд байж байгаад буцаад Япон руугаа ирэхээр, яагаад ч амьдарч чадахаа больдог юм шиг санагдсан. Мэдээж хүн хүнээсээ болох байх. Миний хувьд, хамаг юм Сан Франциско руу ажлаар 1 жил явсанаас л эхэлсэн байх.
Амьдрах хэв маяг, цаг агаар, хүмүүсийн характер, хоорондын харилцаа гээд тэнгэр газар шиг л даа.
Анхнаасаа 1 жил л ажиллах гэрээтэй байсан тул, 1 жил болчихоод буцаад Токио руугаа явлаа. Эхний хэдэн сар, яаж ийм газар насаараа амьдрах юм гэж бодогдоод болдоггүй. Бүүр тэсэхээ байгаад, Сан Франциско дахь салбар руугаа бүр мөсөн шилжихээр бүх бичиг баримтаа хөөцөлдөөд, хүний нөөц болон хэлтсийн даргатайгаа яриад дууслаа.
Эхлээд H1B визээр өгч сугалаанд нь унаад, дараа нь L1 хөөцөлдөж байсан юм. Гэтэл headquarter гэнэт Сан Франциско дахь оффисыг хаахаар шийдээд, миний байсан western маркетийг хариуцдаг байсан багийг тараахаар болов. Үнэхээр ашиг олохгүй байгаа бол тараах нь logical шийдвэр л дээ. Тэгээд нэг сонин багт ороод, тэр цагаас хойш ер нь өөр компани руу оръё гэдгээ бат шийдчихсэн л дээ.
Эхлээд Токио дахь компаниудыг сонирхов. 2 компанид өгөөд уналаа. Тэгэхдээ яагаад ч юм унасандаа сүртэй харамсаагүй санагдаад байна.
Тэгээд нэг өдөр LinkedIn-ээ цэгцлье гэж бодоод, өмнө ирсэн mail-үүдэд хариу бичиж суутал, 2 сарын өмнө Испанид байдаг recruiter залуу Европ руу нүүхгүй биз гэж бичсэн байна.
Эхэндээ serious хүлээж авалгүй зүгээр л сонирхоё гэж бичлээ. Тэгээд Европын хэд хэдэн хотуудад хэдэн компани танилцууллаа. Хамгийн их таалагдсан нь Барселона, Парис 2 л байсан. Германыг уг нь инженерүүдэд их тааламжтай улс гэж сонсож байсан ч, яагаад ч юм Японы Европ хувилбарт оччих юм шиг санагдаад, Барселона, Парис 2т өгч үзэхээр шийдсэн юм. Барселонагийн компанид унасан, хаха.
Парисынх нь одоогийн компани. Skype-аар нийт 6, 7 удаа ярилцлага өгөөд оффероо авлаа. Эхэндээ бас Европ явж амьдрана гэж бодохоор нэг л төсөөлөгдөхгүй байсан тул, болохгүй бол 3 сар ажиллаад буцаад хүрээд ирье гэж бодоод, танидаг хүмүүстэй амралтаар явлаа гээд хэлээд явсан санагдаж байна, худлаа ярьсаныг маань уулчлана гэж найдъя.
Ярилцлагын хувьд:
Ер нь бол Америкийн компаниуд шиг, аймар нарийн кодчилолын чадвар шалгалгүйгээр, resume дээр үндэслээд л, бараг resume нь үнэн байна уу гэж шалгах гэж хэдэн технологийн асуулт асуугаад л болчихдог санагдсан. Мөн ярицлагын ихэнх хэсэг нь, миний юу мэдэх гэхээс илүүтэйгээр, намайг Парист яаж дасан зохицох уу гэдэг дээр л өрнөөд байгаа санагдсан. Стартап компани, мөн инженер эрчимтэй хайж байсан болохоор, сүртэй шалгуур тавиагүй ч байж болох юм.
Ярилцлага бол Япон компаниудыг санагдуулмаар.
Визны хувьд:
Европын холбоо чинь EU Blue Card гээд үнэн дажгүй визтэй юм байна. Тэгэхдээ энэ визний шалгуур болон, нөхцөлүүд нь улс болгон өөр. Жишээ нь Францын хувьд, шалгуур нь Францын дундаж цалингийн 1.5 дахин хэмжээнээс илүү цалин авах ёстой. Мөн виз нь 4 жилээр гарах тул, нэг хэсэгтээ виз сунгана гэж заваарахгүй (Япон 5 жилээр л дээ). Бас нэг нөхцөл нь, эхний 2 жил анх виз авсан компаниа сольж болохгүй. Тэгэхээр би нэг хэсэгтээ энэ компанидаа байна гэсэн үг. Энэ виз нь мөн, компани чинь шаардлагатай бичгийг чинь илгээвэл, маш хурдан гарна (7 хоног ч билүү).
Миний судалснаар, энгийн ажлын виз бас байдаг юм байна лээ. Тэрний нэг асуудалтай тал нь, заавал эндхийн OFII буюу цагаачлалын албанаас зөвшөөрөл авна. Тэр нь гарах эсэх нь мэдэгдэхгүй, гарах гэж бараг сар болно. Мөн гэр бүлтэй бол, тэд нарыгаа өөрийнхөө визэн доор оруулахын тулд, заавал 18 сар энд оршин суусан байх шаардлагатай. Тэгэхдээ 18 сарыг хүлээж байх хоорондоо аялалын визээр ирээд байж болдог л юм шиг байна лээ.
Хэрвээ EU Blue Card-ын талаар сонирхож байвал доорх link-ээр уншаарай
https://www.apply.eu/Questions/